
슬래시 24를 참가했을 당시 토스 증권이 데이터 웨어하우스를 설계 할 때 발생했던 문제들의 해결 과정을 설명한 세션을 보고 작성한 글입니다.
해결하고자 한 문제
- 데이터 분석 전 필요한 데이터를 찾고 필터링 하기까지의 전처리 시간이 오래걸리고 복잡
- ex) 의사 결정자가 체결된 월간 주문건수를 살펴봐 한다면, 주문테이블 체결테이블등에 관련된 테이블들을 다 찾아봐야 하고 날짜별로 필터링 해야하는 등 복잡
데이터 필터링을 미리 해둔 데이터가 있으면 위와 같은 전처리 시간을 줄일 수 있지 않을까?
데이터 필터링을 미리 해두어 저장하자
필요 데이터가 어떤것인지 기준을 잡기 위해, 자주 인입되는 질문들을 유형화
- 유저가 언제 방문했는지 (방문시점)
- 일, 주, 월 단위로 몇 명인지 (기간)
- 이탈/복귀/신규 유저 중 어떤 카테고리에 속하는지 (유저 유형)
토스 증권에서는 이런 활성 유저(Active User)를 기록한 테이블(AU 테이블)을 만들어 사용.
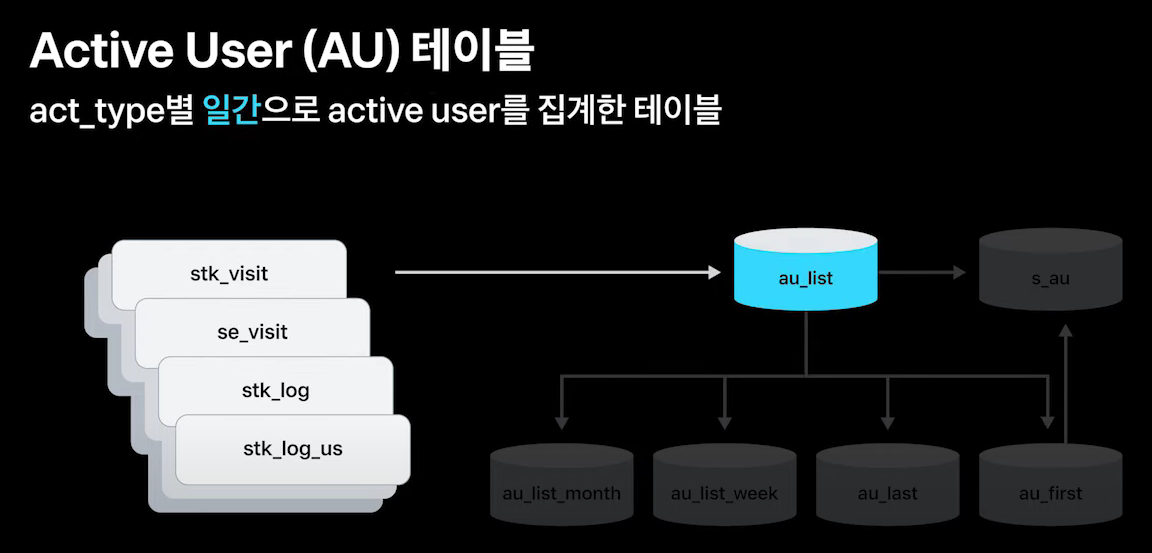
AU 테이블
특정 지표인 act_type 을 정의하고 아래와 같은 형식으로 관리

act_type별 일간으로 활성 유저를 집계한 au_list 테이블을 만들고

au_list 테이블을 기반으로 월간, 주간, 최근, 최초 테이블을 만듦
act_type별 유저가 일간, 최근 7일간, 최근 30일간 activation이 되었는지 집계한 테이블인 s_au 테이블 또한 만들어둠
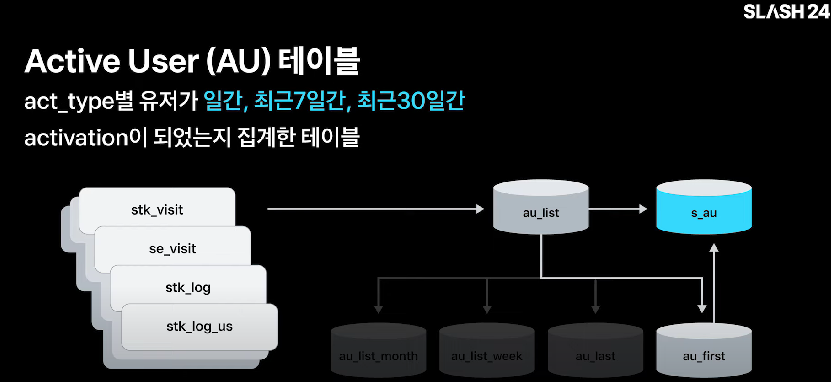
위와 같이 act_type 만 정의하면 일간, 주간, 월간으로 해당 지표의 데이터가 저장되기 때문에 데이터 분석 과정에서의 시간이 많이 절약됨
AU 테이블의 풀고자 했던 문제점
장점이 많았지만, AU 테이블 사용시 아래와 같은 몇 가지 이슈들이 발생

네이밍 컨벤션 통일
네이밍 컨벤션이 없다면, 사용하는 사람이 이 테이블이 존재하는지 유추하기가 어려운게 가장 큰 문제
따라서 테이블, 칼럼 이름 규칙을 만들어서 적용

f_.d_.m_ + 서비스 혹은 주제영역 + 집계단위 + 날짜 단위
act_type 별로 특수하게 집계해야 하는 지표도 저장하고 싶은데
기존에는 AU 테이블이 중간 집계 테이블의 역할만 하고 특정 act_type 별로 따로 저장해야 하는 데이터들을 저장하지 못했음
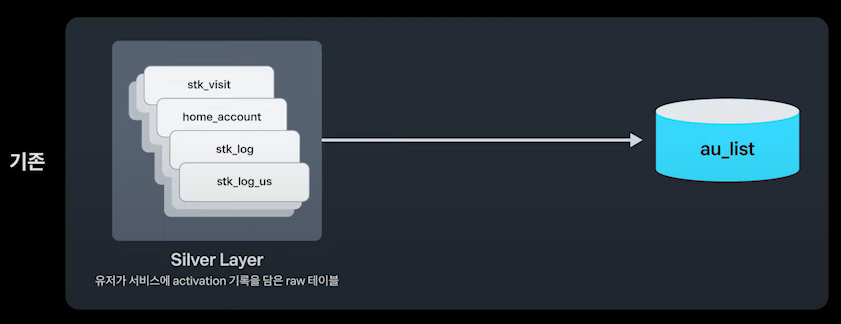
단순 집계하는 중간집계성 테이블에서 벗어나서, 각 act_type 별 필요한 지표가 담긴 마트 테이블을 구축하기로 결정
마트테이블 이란?
특정 부서나 비즈니스 영역을 위한 소규모 데이터 웨어하우스

위 사진에서, 각 act_type 을 키값으로 하는 객체 안에 sum_cols, count_distinct_cols, custom_where_condition 와 같은 값을 설정해두어, 데이터를 집계할때 따로 해당 데이터들도 집계하도록 설정해둔 모습이다.
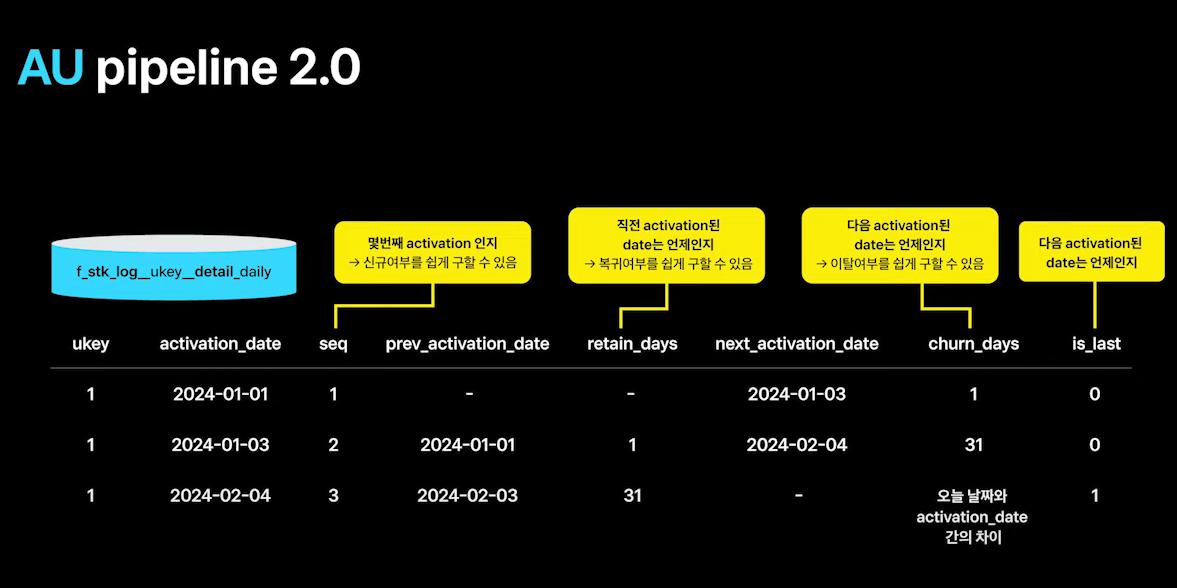
복귀 이탈 유저 집계는 중요한 정보인데..
activation 시점을 기준으로 seq, retain_days 등 복귀 이탈 지표를 저장하는 테이블을 따로 생성성
데이터 집계 flow
airflow 사용해서 집계 하는데 DAG 은 아래와 같다
Airflow 와 DAG
Airflow 는 워크플로우 관리 도구로, 데이터 파이프라인이나 일련의 작업을 자동화하고 스케줄링하는 데 사용
DAG 은 Airflow에서 작업 간의 순서와 의존성을 나타내는 구조
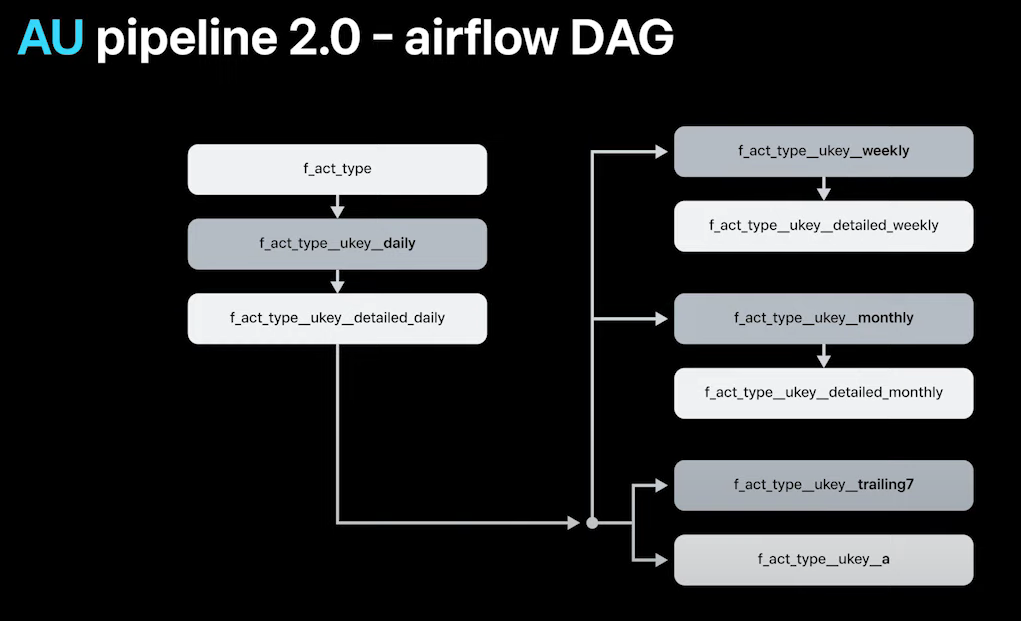
집계순서는 두 줄 요약하면 아래와 같다.
- act_type 별 데이터를 통해 일간 act_type 테이블, 일간 복귀 이탈 유저 테이블 생성
- 위 데이터들로 주간, 월간, 최근 7일 집계 테이블 생성
파이프라인 구축할 때 고려했던 것들
위 작업들을 진행할 때 특히 고려할 사항들은 아래와 같다.
1. 많은 로직들이 반복 실행되기 때문에 코드의 재활용성을 높여야 함
2. 실행시간이 오래 걸리는 작업들을 병렬로 처리하며 실행시간과 메모리를 관리해야 함
3. 많은 테이블이 생성 되기 때문에, 실행 실패했을때 데이터 일관성을 보장해야 하기 때문에 Backfill 에 각별히 주의해야 함.
Backfill 이란?
과거의 실행되지 않은 DAG(Directed Acyclic Graph) 작업을 소급하여 처리하는 작업
토스 증권에서는 아래와 같이 고려했던 사항들을 반영해두었다.
- 코드의 재활용성을 높이기 위해 특정 파일에 테이블 생성 로직 코드를 몰아두어 다른 파일에서 해당 로직들을 끌어다 사용
- act_type 별로 오래 걸리는 task 를 먼저 실행하든 등 각 작업별로 커스텀하게 셋팅

- backfill을 쉽게 할 수 있는 Dag 을 설정
- 긴 기간을 backfill 하는 경우 메모리가 터질 가능성이 크기 때문에 특정 기간을 잘라서 실행하든 방식 또한 고려
이제 처리된 데이터들을 사용해보자
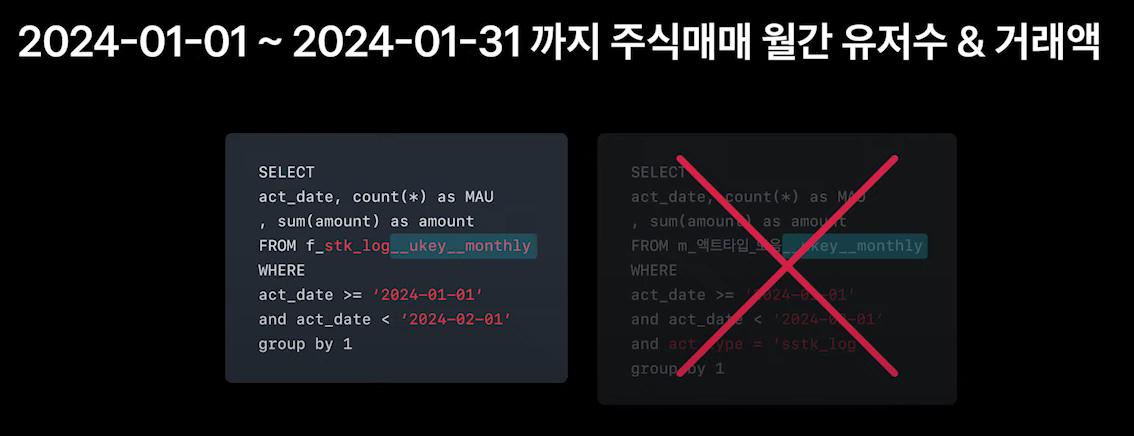
아래와 같이 몇 줄 되지 않는 간단한 sql 질의문으로도 쉽게 요구사항에 따라 데이터를 가져올 수 있음

act_type 별로 다른 특수한 칼럼들도 확인 할 수 있음
- 아래에서 amount 칼럼은 공통 집계 테이블에 없지만, 데이터 파이프라인을 진행하며 따로 집계해두었기 때문에 바로 확인 가능
요약
- 많은 니즈가 있던 요구사항들을 기반으로 데이터를 미리 필터링해서 따로 테이블로 만들어서 데이터 분석하기 전에 데이터를 전처리하는 시간을 줄여보자는 것이 메인 아이디어
- 저장할 테이블의 네이밍 컨벤션을 수립하고 각 집계유형마다 특수하게 집계해야 하는 데이터도 처리
- 데이터 파이프라인 생성할때, 코드 재활용성이나 실행시간 효율성들을 고려하며 파이프라인을 고려하며 설계
결론
마치 쉐프들이 매장 오픈전에 재료들을 prep 해두듯이 데이터들을 전처리 해두는 작업을 보는 것 같았다.
과정에서 실행시간, 코드 재사용성, 메모리 효율성 등을 고려하며 파이프라인을 설계하고 데이터 일관성 유지를 위해 고민하는 과정이 인상 깊었다
저렇게 데이터를 저장해두면 사용할 때 질의문이 복잡해지지 않을 것 같아서 많이 편리할 것 같다.